GCC 工具链基础
GCC 实质上不是一个单独的程序,而是多个程序的集合,因此通常称为 GCC 工具链。工具链软件包括 GCC、C 运行库、Binutils 和 GDB 等等。
- GCC(GNU C Compiler)是编译工具,可以将 C/C++ 语言编写的程序转换成为处理器能够执行的二进制代码。
- GDB(GNU Project Debugger)是调试工具,可以用于对程序进行调试。
Binutils
这是一组二进制程序的处理工具,包括:addr2line、ar、objcopy、objdump、as、ld、ldd、readelf、size等。
- addr2line:用来将程序地址转换成其所对应的程序源文件及所对应的代码行,也可以得到所对应的函数。该工具将帮助调试器在调试的过程中定位对应的源代码位置。
- as:主要用于汇编。
- ld:主要用于链接。
- ar:主要用于创建静态库。
- 如果要将多个
.o目标文件生成一个库文件,则存在两种类型的库,一种是静态库,另一种是动态库。 - 在 Windows 中静态库是以
.lib为后缀的文件,共享库是以.dll为后缀的文件。在 Linux 中静态库是以.a为后缀的文件,共享库是以.so为后缀的文件。 - 静态库和动态库的不同点在于代码被载入的时刻不同。静态库的代码在编译过程中已经被载入可执行程序,因此体积较大。共享库的代码是在可执行程序运行时才载入内存的,在编译过程中仅简单的引用,因此代码体积较小。在 Linux 系统中,可以用
ldd命令查看一个可执行程序依赖的共享库。 - 如果一个系统中存在多个需要同时运行的程序且这些程序之间存在共享库,那么采用动态库的形式将更节省内存。但是对于嵌入式系统,大多数情况下都是整个软件就是一个可执行程序且不支持动态加载的方式,即以静态库为主。
- 如果要将多个
- ldd:可以用于查看一个可执行程序依赖的共享库。
- objcopy:将一种对象文件翻译成另一种格式,比如将
.bin转换成.elf、或者将.elf转换成.bin等。 - objdump:主要的作用是反汇编。
- readelf:显示有关
ELF文件的信息。 - size:列出可执行文件每个部分的尺寸和总尺寸,代码段、数据段、总大小等。
C 运行库
C语言标准主要由两部分组成:一部分描述 C 的语法,另一部分描述 C 标准库。C 标准库定义了一组标准头文件,每个头文件中包含一些相关的函数、变量、类型声明和宏定义,比如常见的 printf 函数便是一个 C 标准库函数,其原型定义在 stdio 头文件中。
C 语言标准仅仅定义了 C 标准库函数原型,并没有提供实现。因此,C 编译器需要一个 C 运行时库(C Run Time Libray,CRT)的支持。
glibc (GNU C Library) 是 Linux 下的 C 标准库的实现:
-
glibc 本身是 GNU 旗下的 C 标准库,后来逐渐成为了 Linux 的标准 C 库。glibc 的主体分布在 Linux 系统的 /lib 与 /usr/lib 目录中,包括 libc 标准 C 函数库、libm 数学函式库等,都以
.so结尾。Linux 系统下的标准 C 库不只有 glibc,还存在 uclibc、klibc、musl 等等,但是 glibc 使用最为广泛。
嵌入式系统中使用较多的 C 运行库是
newlib。 -
Linux 系统通常将 libc 库作为操作系统的一部分,它被视为操作系统与用户程序的接口。比如:glibc 不仅实现标准 C 语言中的函数,还封装了操作系统提供的系统调用。
- 通常情况,每个特定的系统调用对应了至少一个 glibc 封装的库函数,比如系统调用
sys_open对应的是glibc 中的open函数;其次,glibc 一个单独的 API 可能会调用多个系统调用,比如printf函数会调用如sys_open、sys_mmap、sys_write、sys_close等系统调用;另外,多个 glibc API 也可能对应同一个系统调用,如 glibc 下实现的malloc、free等函数用来分配和释放内存,都是基于内核的sys_brk的系统调用。
- 通常情况,每个特定的系统调用对应了至少一个 glibc 封装的库函数,比如系统调用
-
对于 C++ 语言,常用的 C++ 标准库为
libstdc++。通常libstdc++与 GCC 捆绑在一起的,即安装 gcc 的时候会把 libstdc++ 装上。而 glibc 并没有和 GCC 捆绑于一起,这是因为 glibc 需要与操作系统内核打交道,因此其与具体的操作系统平台紧密耦合。而 libstdc++ 虽然提供了 c++ 程序的标准库,但其并不与内核打交道。对于系统级别的事件,libstdc++ 会与 glibc 交互,从而和内核通信。
编译过程
准备 Hello World 程序
#include <stdio.h>
int main(void)
{
printf("Hello World! \n");
return 0;
}
预处理
预处理的过程主要包括以下过程:
- 将所有的
#define删除,并且展开所有的宏定义,并且处理所有的条件预编译指令,比如#if#ifdef#elif#else#endif等。 - 处理
#include预编译指令,将被包含的文件插入到该预编译指令的位置。 - 删除所有注释
//和/**/。 - 添加行号和文件标识,以便编译时产生调试用的行号及编译错误警告行号。
- 保留所有的
#pragma编译器指令,后续编译过程需要使用它们。
使用 gcc 进行预处理的命令如下:
gcc -E hello.c -o hello.i # 将源文件 hello.c 文件预处理生成 hello.i
hello.i 文件可以作为普通文本文件打开进行查看,其代码片段如下所示:
extern void funlockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__));
# 942 "/usr/include/stdio.h" 3 4
# 2 "hello.c" 2
# 3 "hello.c"
int
main(void)
{
printf("Hello World!" "\n");
return 0;
}
编译
编译过程就是对预处理完的文件进行一系列的词法分析,语法分析,语义分析及优化后生成相应的汇编代码。
使用 gcc 进行编译的命令如下:
gcc -S hello.i -o hello.s # 将预处理生成的 hello.i 文件编译生成汇编程序 hello.s
上述命令生成的汇编程序 hello.s 的代码片段如下所示,其全部为汇编代码。
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl $.LC0, %edi
call puts
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
汇编
汇编过程调用对汇编代码进行处理,生成处理器能识别的指令,保存在后缀为 .o 的目标文件中。由于每一个汇编语句几乎都对应一条处理器指令,因此,汇编相对于编译过程比较简单,通过调用 Binutils 中的汇编器 as 根据汇编指令和处理器指令的对照表一一翻译即可。
当程序由多个源代码文件构成时,每个文件都要先完成汇编工作,生成 .o 目标文件后,才能进入下一步的链接工作。注意:目标文件已经是最终程序的某一部分了,但是在链接之前还不能运行。
使用 gcc 进行汇编的命令如下:
gcc -c hello.s -o hello.o # 将编译生成的 hello.s 文件汇编生成目标文件 hello.o
# 或者直接调用 as 进行汇编
as -c hello.s -o hello.o # 使用 Binutils 中的 as 将 hello.s 文件汇编生成目标文件
:::warning
hello.o 目标文件为 ELF(Executable and Linkable Format) 格式的可重定向文件。
:::
链接
经过汇编以后的目标文件还不能直接运行,为了变成能够被加载的可执行文件,文件中必须包含固定格式的信息头,还必须与系统提供的启动代码链接起来才能正常运行,这些工作都是由链接器来完成的。
GCC 可以通过调用 Binutils 中的链接器 ld 来链接程序运行需要的所有目标文件,以及所依赖的其它库文件,最后生成一个 ELF 格式可执行文件。
如果直接调用 Binutils 中的ld 进行链接,命令如下,则会报出错误:
# 直接调用ld试图将hello.o文件链接成为最终的可执行文件hello
ld hello.o –o hello
ld: warning: cannot find entry symbol _start; defaulting to 00000000004000b0
hello.o: In function `main':
hello.c:(.text+0xa): undefined reference to `puts'
之所以直接用 ld 进行链接会报错是因为仅仅依靠一个 hello.o 目标文件还无法链接成为一个完整的可执行文件,需要明确的指明其需要的各种依赖库和引导程序以及链接脚本,此过程在嵌入式软件开发时是必不可少的。而在 Linux 系统中,可以直接使用 gcc 命令执行编译直至链接的过程,gcc 会自动将所需的依赖库以及引导程序链接在一起成为 Linux 系统可以加载的 ELF 格式可执行文件。使用 gcc 进行编译直至链接的命令如下:
gcc hello.c -o hello # 将 hello.c 文件编译汇编链接生成可执行文件 hello
./hello # 成功执行该文件,在终端上会打印 Hello World!字符串 Hello World!
注意:hello 可执行文件为 ELF(Executable and Linkable Format)格式的可执行文件。
链接分为静态链接和动态链接:
-
静态链接是指在编译阶段直接把静态库加入到可执行文件中去,这样可执行文件会比较大。链接器将函数的代码从其所在地(不同的目标文件或静态链接库中)拷贝到最终的可执行程序中。为创建可执行文件,链接器必须要完成的主要任务是:符号解析(把目标文件中符号的定义和引用联系起来)和重定位(把符号定义和内存地址对应起来然后修改所有对符号的引用)。
-
而动态链接则是指链接阶段仅仅只加入一些描述信息,而程序执行时再从系统中把相应动态库加载到内存中去。
- 在 Linux 系统中,gcc 编译链接时的动态库搜索路径的顺序通常为:首先从 gcc 命令的参数
-L指定的路径寻找;再从环境变量LIBRARY_PATH指定的路径寻址;再从默认路径/lib、/usr/lib、/usr/local/lib中寻找。 - 在 Linux 系统中,执行二进制文件时的动态库搜索路径的顺序通常为:首先搜索编译目标代码时指定的动态库搜索路径;再从环境变量
LD_LIBRARY_PATH指定的路径寻址;再从配置文件/etc/ld.so.conf中指定的动态库搜索路径;再从默认路径/lib、/usr/lib中寻找。 - 在 Linux 系统中,可以用
ldd命令查看一个可执行程序依赖的共享库。
- 在 Linux 系统中,gcc 编译链接时的动态库搜索路径的顺序通常为:首先从 gcc 命令的参数
-
由于链接动态库和静态库的路径可能有重合,所以如果在路径中有同名的静态库文件和动态库文件,比如libtest.a 和 libtest.so,gcc 链接时默认优先选择动态库,会链接 libtest.so,如果要让 gcc 选择链接 libtest.a则可以指定 gcc 选项
-static,该选项会强制使用静态库进行链接。-
如果使用命令
gcc hello.c -o hello则会使用动态库进行链接,生成的 ELF 可执行文件的大小(使用Binutils 的size命令查看)和链接的动态库(使用 Binutils 的ldd命令查看)如下所示:$ gcc hello.c -o hello $ size hello # 使用size查看大小 text data bss dec hex filename 1183 552 8 1743 6cf hello $ ldd hello # 可以看出该可执行文件链接了很多其他动态库,主要是 Linux 的 glibc 动态库 linux-vdso.so.1 => (0x00007fffefd7c000) libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fadcdd82000) /lib64/ld-linux-x86-64.so.2 (0x00007fadce14c000) -
如果使用命令
gcc -static hello.c -o hello则会使用静态库进行链接,生成的 ELF 可执行文件的大小和链接的动态库如下所示:$ gcc -static hello.c -o hello $ size hello # 使用size查看大小 text data bss dec hex filename 823726 7284 6360 837370 cc6fa hello # 可以看出 text 段的代码尺寸变大 $ ldd hello not a dynamic executable # 说明没有链接动态库
-
链接器链接后生成的最终文件为 ELF 格式可执行文件,一个 ELF 可执行文件通常被链接为不同的段,常见的段有 .text、.data、.rodata、.bss 等。
一步到位的编译
从功能上分,预处理、编译、汇编、链接是四个不同的阶段,但 GCC 的实际操作上,它可以把这四个步骤合并为一个步骤来执行。如下例所示:
gcc –o test first.c second.c third.c
# 该命令将同时编译三个源文件,即 first.c、second.c 和 third.c,然后将它们链接成一个可执行文件
注意:
- 一个程序无论有一个源文件还是多个源文件,所有被编译和链接的源文件中必须有且仅有一个
main函数。 - 但如果仅仅是把源文件编译成目标文件,因为不会进行链接,所以
main函数不是必需的。
分析 ELF 文件
ELF 文件介绍
在介绍ELF文件之前,首先将其与另一种常见的二进制文件格式bin进行对比:
- binary文件,其中只有机器码。
- elf文件除了含有机器码之外还有其它信息,如:段加载地址,运行入口地址,数据段等。
ELF全称Executable and Linkable Format,可执行链接格式。ELF文件格式主要三种:
- 可重定向(Relocatable)文件:
- 文件保存着代码和适当的数据,用来和其他的目标文件一起来创建一个可执行文件或者是一个共享目标文件。
- 可执行(Executable)文件:
- 文件保存着一个用来执行的程序(例如bash,gcc等)。
- 共享(Shared)目标文件(Linux下后缀为.so的文件):
- 即所谓共享库。
ELF文件的段
ELF文件格式如图1中所示,位于ELF Header和Section Header Table之间的都是段(Section)。一个典型的ELF文件包含下面几个段:
- .text:已编译程序的指令代码段。
- .rodata:ro代表read only,即只读数据(譬如常数const)。
- .data:已初始化的C程序全局变量和静态局部变量。
- 注意:C程序普通局部变量在运行时被保存在堆栈中,既不出现在.data段中,也不出现在.bss段中。此外,如果变量被初始化值为0,也可能会放到bss段。
- .bss:未初始化的C程序全局变量和静态局部变量。
- 注意:目标文件格式区分初始化和未初始化变量是为了空间效率,在ELF文件中.bss段不占据实际的存储器空间,它仅仅是一个占位符。
- .debug:调试符号表,调试器用此段的信息帮助调试。
- 上述仅讲解了最常见的节,ELF文件还包含很多其他类型的节,本文在此不做赘述,请感兴趣的读者自行查阅其他资料了解学习。
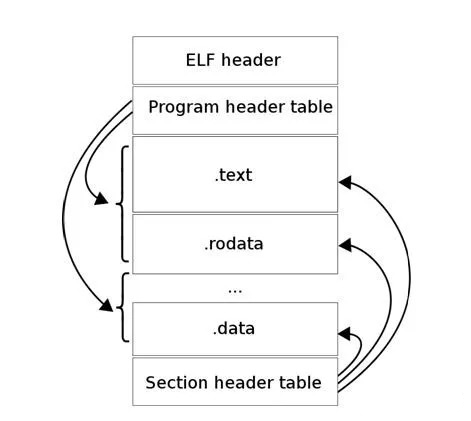
查看ELF文件
可以使用Binutils中readelf来查看ELF文件的信息,可以通过readelf --help来查看readelf的选项:
$ readelf --help
Usage: readelf <option(s)> elf-file(s)
Display information about the contents of ELF format files
Options are:
-a --all Equivalent to: -h -l -S -s -r -d -V -A -I
-h --file-header Display the ELF file header
-l --program-headers Display the program headers
--segments An alias for --program-headers
-S --section-headers Display the sections' header
以本文Hello World示例,使用readelf -S查看其各个section的信息如下:
$ readelf -S hello
There are 31 section headers, starting at offset 0x19d8:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
……
[11] .init PROGBITS 00000000004003c8 000003c8
000000000000001a 0000000000000000 AX 0 0 4
……
[14] .text PROGBITS 0000000000400430 00000430
0000000000000182 0000000000000000 AX 0 0 16
[15] .fini PROGBITS 00000000004005b4 000005b4
……
反汇编
由于ELF文件无法被当做普通文本文件打开,如果希望直接查看一个ELF文件包含的指令和数据,需要使用反汇编的方法。反汇编是用于调试和定位处理器问题时最常用的手段。 可以使用Binutils中objdump来对ELF文件进行反汇编,可以通过objdump --help来查看其选项:
$ objdump --help
Usage: objdump <option(s)> <file(s)>
Display information from object <file(s)>.
At least one of the following switches must be given:
……
-D, --disassemble-all Display assembler contents of all sections
-S, --source Intermix source code with disassembly
……
以本文Hello World示例,使用objdump -D对其进行反汇编如下:
$ objdump -D hello
……
0000000000400526 <main>: # main标签的PC地址
# PC地址: 指令编码 指令的汇编格式
400526: 55 push %rbp
400527: 48 89 e5 mov %rsp,%rbp
40052a: bf c4 05 40 00 mov $0x4005c4,%edi
40052f: e8 cc fe ff ff callq 400400 <puts@plt>
400534: b8 00 00 00 00 mov $0x0,%eax
400539: 5d pop %rbp
40053a: c3 retq
40053b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
……
使用objdump -S将其反汇编并且将其C语言源代码混合显示出来:
$ gcc -o hello -g hello.c # 要加上-g选项
$ objdump -S hello
……
0000000000400526 <main>:
#include <stdio.h>
int
main(void)
{
400526: 55 push %rbp
400527: 48 89 e5 mov %rsp,%rbp
printf("Hello World!" "\n");
40052a: bf c4 05 40 00 mov $0x4005c4,%edi
40052f: e8 cc fe ff ff callq 400400 <puts@plt>
return 0;
400534: b8 00 00 00 00 mov $0x0,%eax
}
400539: 5d pop %rbp
40053a: c3 retq
40053b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
……
嵌入式系统编译的特殊性
为了易于读者理解,本文以一个Hello World程序为例讲解了在Linux环境中的编译过程以帮助初学者入门,但是了解这些基础背景知识对于嵌入式开发还远远不够。 对于嵌入式开发,嵌入式系统的编译过程和开发有其特殊性,譬如:
- 嵌入式系统需要使用交叉编译与远程调试的方法进行开发。
- 需要自己定义引导程序。
- 需要注意减少代码尺寸。
- 需要移植printf从而使得嵌入式系统也能够打印输入。
- 使用Newlib作为C运行库。
- 每个特定的嵌入式系统都需要配套的板级支持包。
交叉编译和远程调试
嵌入式平台上往往资源有限,嵌入式系统(譬如常见ARM MCU或8051单片机)的存储器容量通常只在几KB到几MB之间,且只有闪存而没有硬盘这种大容量存储设备,在这种资源有限的环境中,不可能将编译器等开发工具安装在嵌入式设备中,所以无法直接在嵌入式设备中进行软件开发。因此,嵌入式平台的软件一般在主机PC上进行开发和编译,然后将编译好的二进制代码下载至目标嵌入式系统平台上运行,这种编译方式属于交叉编译。
交叉编译可以简单理解为,在当前编译平台下,编译出来的程序能运行在体系结构不同的另一种目标平台上,但是编译平台本身却不能运行该程序,譬如,在x86平台的PC电脑上编写程序并编译成能运行在ARM平台的程序,编译得到的程序在x86平台上不能运行,必须放到ARM平台上才能运行。
与交叉编译同理,在嵌入式平台上往往也无法运行完整的调试器,因此当运行于嵌入式平台上的程序出现问题时,需要借助主机PC平台上的调试器来对嵌入式平台进行调试。这种调试方式属于远程调试。
常见的交叉编译和远程调试工具是GCC和GDB。GCC不仅能作为本地编译器,还能作为交叉编译器;同理GDB不仅可以作为本地调试器,还可以作为远程调试器。
当作为交叉编译器之时,GCC通常有不同的命名,譬如:
- arm-none-eabi-gcc和arm-none-eabi-gdb是面向裸机(Bare-Metal)ARM平台的交叉编译器和远程调试器。
- 所谓裸机(Bare-Metal)是嵌入式领域的一个常见形态,表示不运行操作系统的系统
- 而riscv-none-embed-gcc和riscv-none-embed-gdb是面向裸机RISC-V平台的交叉编译器和远程调试器。
移植newlib或newlib-nano作为C运行库
newlib是一个面向嵌入式系统的C运行库。相对于glibc,newlib实现了大部分的功能函数,但体积却小很多。newlib独特的体系结构将功能实现与具体的操作系统分层,使之能够很好地进行配置以满足嵌入式系统的要求。由于专为嵌入式系统设计,newlib具有可移植性强、轻量级、速度快、功能完备等特点,已广泛应用于各种嵌入式系统中。
由于嵌入式操作系统和底层硬件的多样性,为了能够将C/C++语言所需要的库函数实现与具体的操作系统和底层硬件进行分层,newlib的所有库函数都建立在20个桩函数的基础上,这20个桩函数完成具体操作系统和底层硬件相关的功能:
- I/O和文件系统访问(open、close、read、write、lseek、stat、fstat、fcntl、link、unlink、rename);
- 扩大内存堆的需求(sbrk);
- 获得当前系统的日期和时间(gettimeofday、times);
- 各种类型的任务管理函数(execve、fork、getpid、kill、wait、_exit);
这20个桩函数在语义、语法上与POSIX(Portable Operating System Interface of UNIX)标准下对应的20个同名系统调用完全兼容。
所以,如果需要移植newlib至某个目标嵌入式平台,成功移植的关键是在目标平台下找到能够与newlib桩函数衔接的功能函数或者实现这些桩函数。
注意:newlib的一个特殊版本newlib-nano版本进一步为嵌入式平台减少了代码体积(Code Size),因为newlib-nano提供了更加精简版本的malloc和printf函数的实现,并且对库函数使用GCC的-Os(侧重代码体积的优化)选项进行编译优化。
嵌入式引导程序和中断异常处理
前文介绍了如何在Linux系统的PC电脑上开发一个Hello World程序,对其进行编译,然后运行在此电脑上。在这种方式下,程序员仅仅只需要关注Hello World程序本身,程序的主体由main函数组织而成,程序员可以无需关注Linux操作系统在运行该程序的main函数之前和之后需要做什么。事实上,在Linux操作系统中运行应用程序(譬如简单的Hello World)时,操作系统需要动态地创建一个进程、为其分配内存空间、创建并运行该进程的引导程序,然后才会开始执行该程序的main函数,待其运行结束之后,操作系统还要清除并释放其内存空间、注销该进程等。
从上述过程中可以看出,程序的引导和清除这些“脏活累活”都是由Linux这样的操作系统来负责进行。但是在嵌入式系统中,程序员除了开发以main函数为主体的功能程序之外,还需要关注如下两个方面:
- 引导程序:
- 嵌入式系统上电后需要对系统硬件和软件运行环境进行初始化,这些工作往往由用汇编语言编写的引导程序完成。
- 引导程序是嵌入式系统上电后运行的第一段软件代码。引导程序对于嵌入式系统非常关键,引导程序所执行的操作依赖于所开发的嵌入式系统的软硬件特性,一般流程包括:初始化硬件、设置异常和中断向量表、把程序拷贝到片上SRAM中、完成代码的重映射等,最后跳转到main函数入口。
- 中断异常处理
- 中断和异常是嵌入式系统非常重要的一个环节,因此,嵌入式系统软件还必须正确地配置中断和异常处理函数。
嵌入式系统链接脚本
上文中介绍了如何在Linux系统的PC电脑上开发一个Hello World程序,对其进行编译,然后运行在此电脑上。在这种方式下,程序员也无需关心编译过程中的“链接”这一步骤所使用的链接脚本,无需为程序分配具体的内存空间。
但是在嵌入式系统中,程序员除了开发以main函数为主体的功能程序之外,还需要关注“链接脚本”为程序分配合适的存储器空间,譬如程序段放在什么区间、数据段放在什么区间等等。
减小代码体积
嵌入式平台上往往存储器资源有限,嵌入式系统(譬如常见的ARM MCU或8051单片机)的存储器容量通常只在几KB到几MB之间,且只有闪存而没有硬盘这种大容量存储设备,在这种资源有限的环境中,程序的代码体积(Code Size)显得尤其重要,因此,有效地降低降低代码体积(Code Size)是嵌入式软件开发必须要考虑的问题,常见的方法如:
- 使用newlib-nano作为C运行库以取得较小代码体积(Code Size)的C库函数。
- 尽量少使用C语言的大型库函数,譬如在正式发行版本的程序中避免使用printf和scanf等函数。
- 如果在开发的过程中一定需要使用printf函数,可以使用某些自己实现的阉割版printf函数(而不是C运行库中提供的printf函数)以生成较小的代码体积。
- 除此之外,在C/C++语言的语法和程序开发方面也有众多技巧以取得更小的代码体积(Code Size)。
支持printf函数
上文中介绍了如何在Linux系统的PC电脑上开发一个Hello World程序,程序中使用C语言的标准库函数printf打印了一个“Hello World”字符串。该程序在Linux系统里面运行的时候字符串被成功的输出到了Linux的终端界面上。在这个过程中,程序员无需关心Linux系统到底是如何将printf函数的字符串输出到Linux终端上的。事实上,在Linux本地编译的程序会链接使用Linux系统的C运行库glibc,而glibc充当了应用程序和Linux操作系统之间的接口,glibc提供的 printf 函数就会调用如sys_write等操作系统的底层系统调用函数,从而能够将“字符串”输出到Linux终端上。
从上述过程中可以看出,由于有glibc的支持,所以printf函数能够在Linux系统中正确的进行输出。但是在嵌入式系统中,printf的输出却不那么容易了,基于如下几个原因:
- 嵌入式系统使用newlib作为C运行库,而newlib的C运行库所提供的printf函数最终依赖于如本文中所介绍的newlib桩函数write,因此必须实现此write函数才能够正确的执行printf函数。
- 嵌入式系统往往没有“显示终端”存在,譬如常见的单片机其作为一个黑盒子一般的芯片,根本没有显示终端。因此,为了能够支持显示输出,通常需要借助单片机芯片的UART接口将printf函数的输出重新定向到主机PC的COM口上,然后借助主机PC的串口调试助手显示出输出信息。同理,对于scanf输入函数,也需要通过主机PC的串口调试助手获取输入然后通过主机PC的COM口发送给单片机芯片的UART接口。
- 从以上两点可以看出,嵌入式平台的UART接口非常重要,往往扮演了输出管道的角色,为了能够将printf函数的输出定向到UART接口,需要实现newlib的桩函数write,使其通过编程UART的相关寄存器将字符通过UART接口输出。
提供板级支持包
对于特定的嵌入式硬件平台,为了方便用户在硬件平台上开发嵌入式程序,硬件平台一般会提供板级支持包(Board Support Package,BSP)。板级支持包所包含的内容没有绝对的标准,通常说来,其必须包含如下内容:
- 底层硬件设备的地址分配信息
- 底层硬件设备的驱动函数
- 系统的引导程序
- 中断和异常处理服务程序
- 系统的链接脚本
- 如果使用newlib作为C运行库,一般还提供newlib桩函数的实现。